Introduction
Artificial Intelligence (AI), machine learning (ML) and deep learning (DL) seem to be taking the world by storm, allowing simple creation of things that were previously, digitally impossible. No sector appears to be safe.
But does the hype exceed reality? Does this mean we will all be programming neural networks? Or will every business be replaced by one of the big five tech companies or a fresh start up?
In what follows, we will explain what Artificial Intelligence, Machine Learning and Deep Learning are and what they could mean for your company. We will do this by:
- introducing the concepts;
- showing some practical applications;
- explaining ‘why now’;
- debunking some hardcore myths.

We fully understand that AI is somewhat of a hype these days, but we will try to stay far from the hype, and focus on:
- actual and practical applications;
- what does and does not work;
- how you can be successful.

So, we like to keep our head in the clouds…

… but our feet on the ground.
Definitions
Sometimes it seems like Artificial Intelligence, Machine Learning and Deep Learning, can used interchangeably. However, there is a clear way to define and link these concepts together.
Let us start with some definitions.

Artificial Intelligence
Artificial Intelligence (AI) is the broad family of technologies trying to capture and mimic human intelligence.

Now what does that mean?
Computers are amazing at processing a lot of data. Take a spreadsheet for example. Computers are capable of linking an insane amount of data points and formulas, instantly churning out results that are impossible for humans to calculate.

The same goes for websites. Computers render the html, css and javascript code on different screens and devices, seemingly effortless…

However, when it comes down to recognizing different animals computers tend to have a hard time.
For humans, this is pretty easy. We can quickly recognize a lion, an elephant and most of the animals in the picture… Even when we see them from a different angle, we can usually tell what animal it is.
When we do not know one of the animals in the picture, it takes no effort for humans to learn for example that the bird is a ‘King Fisher’. Next time you see that bird, you will remember it is a ‘King Fisher’, even only after seeing it once.
Yet, regardless of all the power, computers have had a hard time doing this.

The same goes for large pieces of text. Computers have no trouble parsing and visualizing text, but are mostly unable to graps context, humor, or sarcasm… Something humans pick along the way…
In its ‘simplest’ form we are trying to look for ways to solve problems without explicitely telling the computer how to solve them.
Take the maze as an example, instead of specifying the exact steps to find the path through a particular maze, we can define strategies for the computer to find its way through any maze, much like humans do.
Have a look at the visualization of the “breadth first” and “depth first” approaches to finding the exit: BFS-DFS-pathfinder.
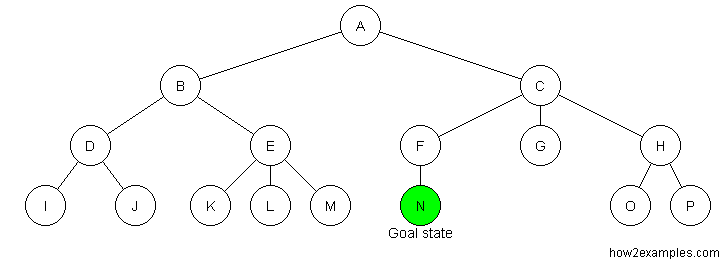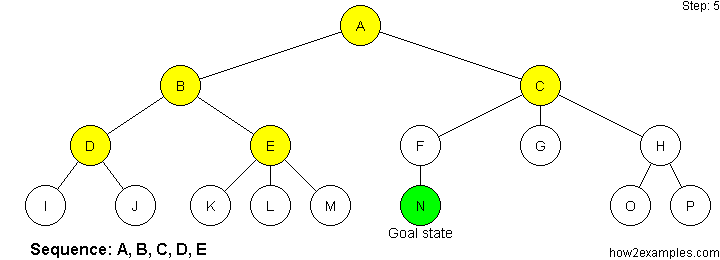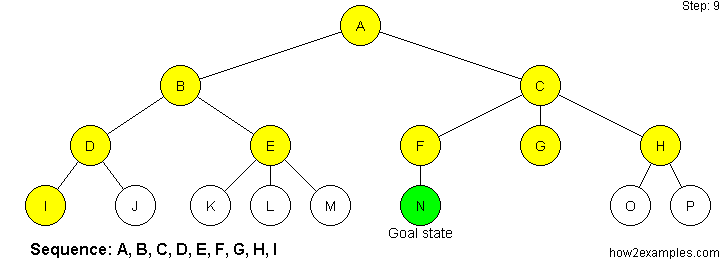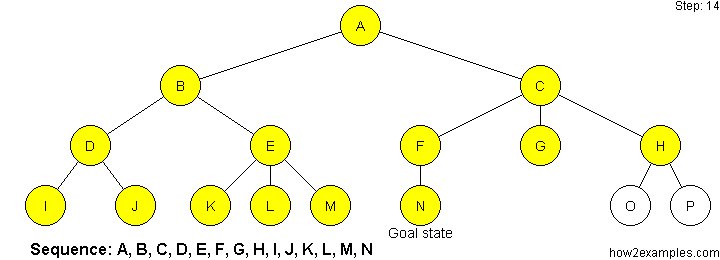
We can also visualize these strategies as a decision tree below.
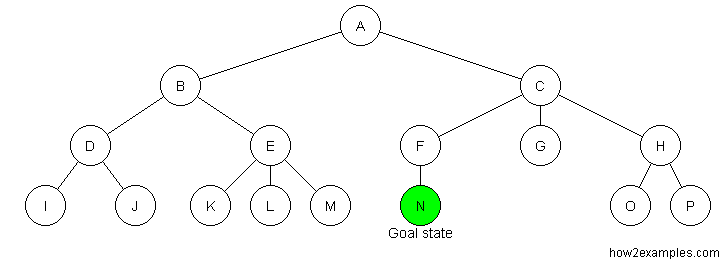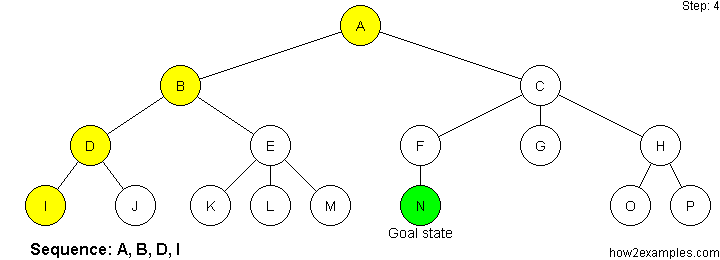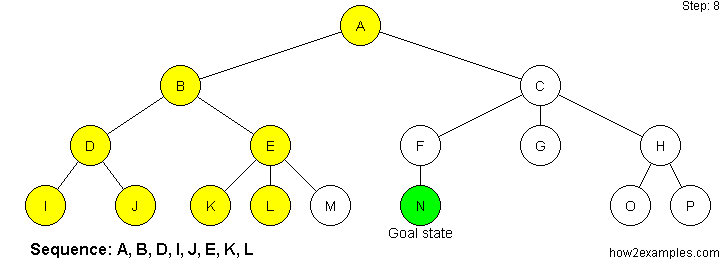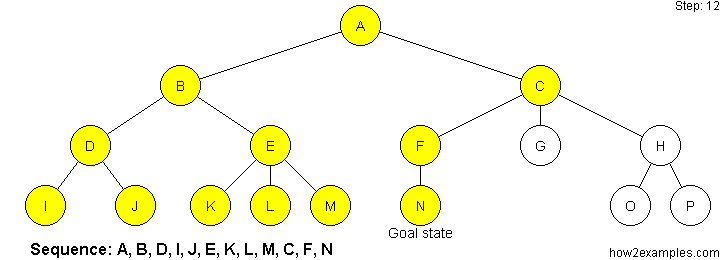
Depth First Search:
Follow the decision tree along one path, all the way to the end (leafs), and backtrack from there until you reach the goal.
Breadth First Search:
From the root, first explore all the neighbor nodes, and move deeper from there, until you reach the goal.
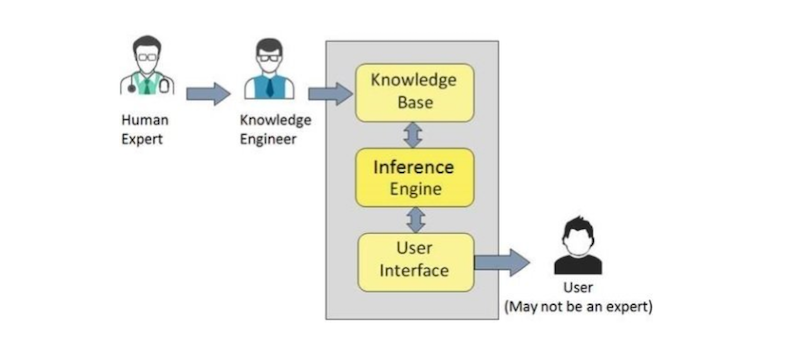
Knowledge base (expert) sytems are another way of trying to capture human knowledge into a machine. A knowledge engineer tries to capture the knowledge from a human domain expert and creates a knowledge base that can be used by a non-expert to get answers to questions.
In practice this usually boils down to “if-then-else”-statements, that are hard to maintain over time.
In 1997, IBM’s Deep Blue was able to beat the reigning world chess champion, Gary Kasparov. It was seen as a sign of the rise of the machine and artificial intelligence, but was later preceived as more of a ‘brute force’ method than of actual intelligence.

Machine Learning
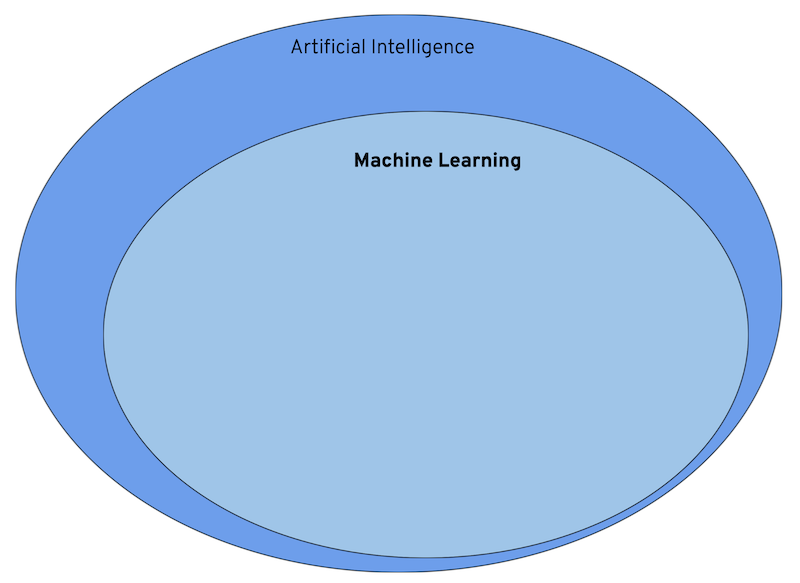
Machine learning is a subset of AI. And before we give a formal definition, we will use a small example from the real world.
In “traditional” programming, the programmer writes the software that uses some data which leads to a result.
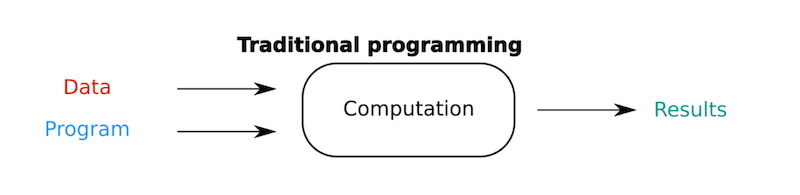
As a concrete example, let us look at a money transfer in a banking app.

The programmer knows exactly how to authenticate the user, fetch its accounts, check the balance and transfer a given amount on a certain date to another account, wich some message.
The data being used reaches from user credentials, to account data, amounts etc…
In the machine learning approach, however, we will use the data and the matching results, to, by learning the relationships between data and results, produce a ‘program’ that is able to predict the results from inputs it has not seen before.
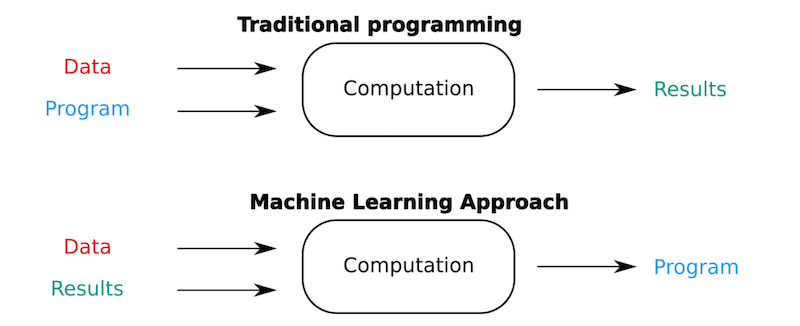
Let’s read that again:
- in machine learning
- we use the input data and matching results (output)
- to learn the relationship between input and outputs
- to produce a ‘program’
- that is able to predict the output from inputs it has never seen.
Here is an informal defintion:

As a more formal defition, we use the one below:

To be honest, I had to read that definition a couple of times before it started to make sense.
To make it more digestible, we will have a look at two examples:
- playing checkers

- recognizing cats

It boils down to: the more the computer looks at cats or plays checkers, the better it should become.
In machine learning, two of the most common applications are classification and regression.
In regression we try to predict a value giving a number of inputs. For example:
- given the day of week, temperature, and chance of rain: how many ice creams will be sold?
- given the size, location, and type of real estate: how much is it worth?
- given the time of day and type of post: how many likes will a social media post receive?
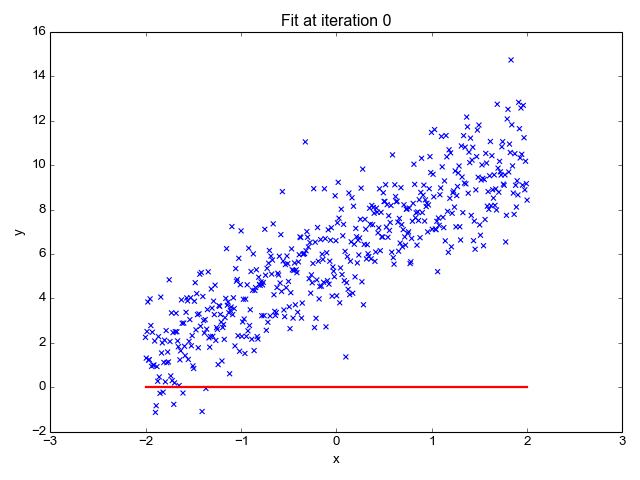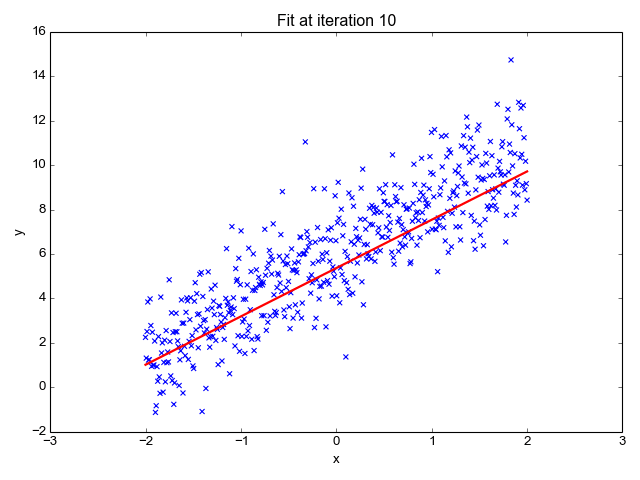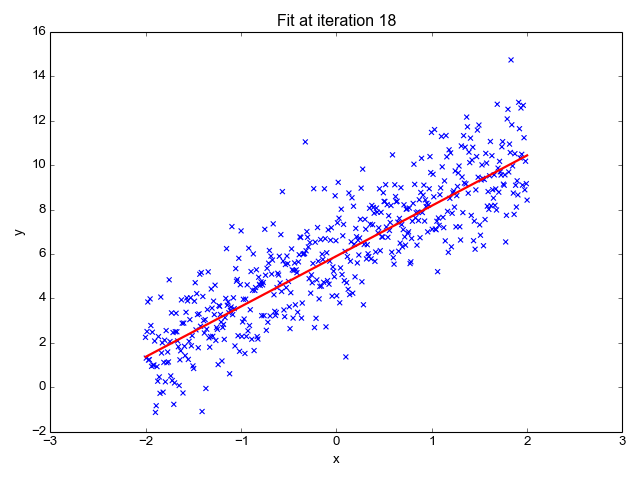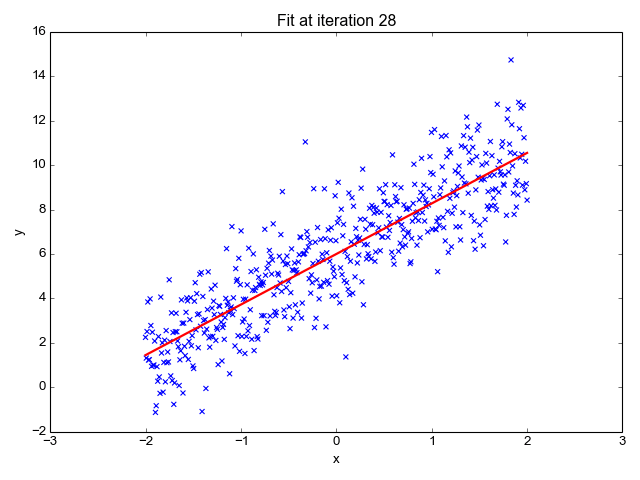
In classification we try to predict the class an input or set of inputs belongs to. For example:
- is an incoming email spam or not?
- is a credit card transaction fraudulent?
- is tumor malginent or benign?

One way to classify inputs is to create a decision tree, which, by using a set of “if-then-else” evalutions, guides you to which class an input belongs.
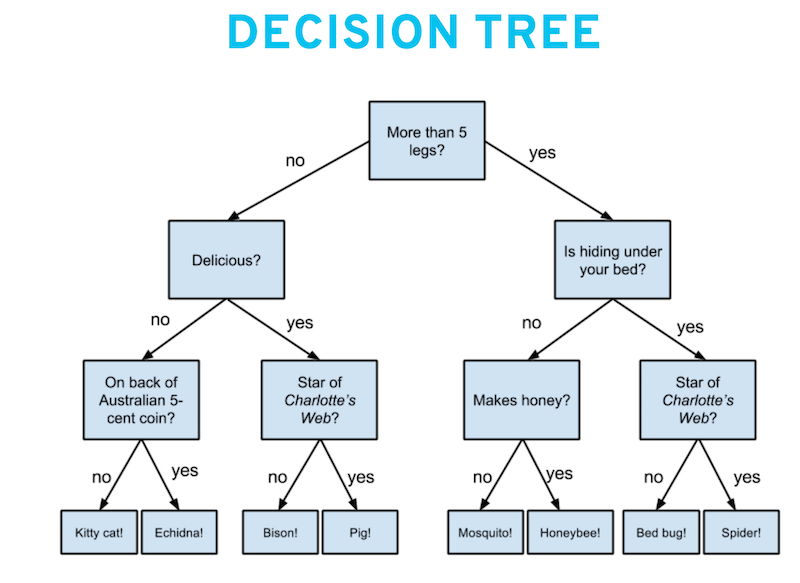
However, instead of crafting it ourselves, we can try to have a computer learn it from examples.
If we combine a number of decision trees, we get what is known as a “random forest”.
We simply use multiple decision trees to make a suggestion for the output (class or value) and in the final step we use a way (“voting”, “averaging”,…) to combine the results of individual trees to one final outputrN.
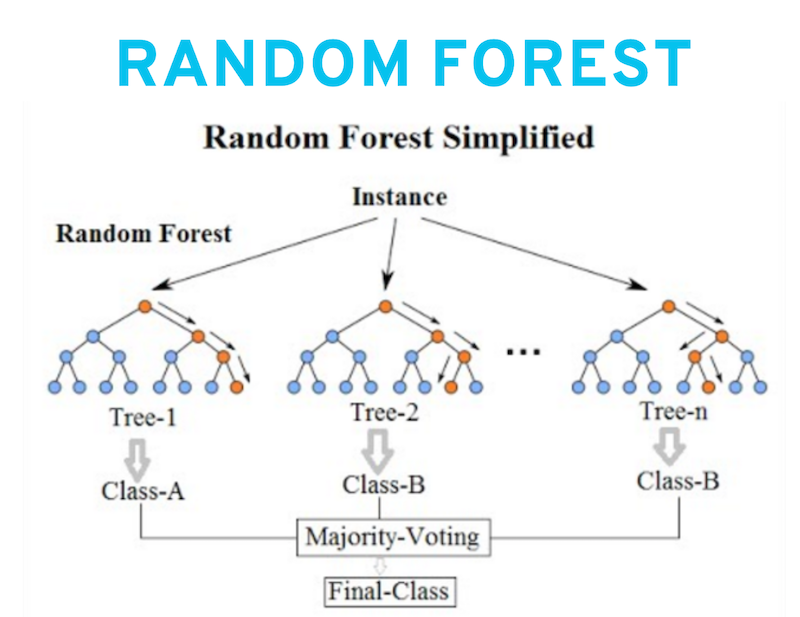
A technique that won a lot of attention the last few years - although the idea has been around for decades - is “neural networks”, which in essence builds a mapping from inputs
- an image
- text
- numerical data))
to outputs
- “malignent” or “benign”;
- “spam” or “not spam”;
- 74 ice creams sold.

In a lot of introductions to “neural networks” you will find they are modeled after the brain, and then show you the picture below:
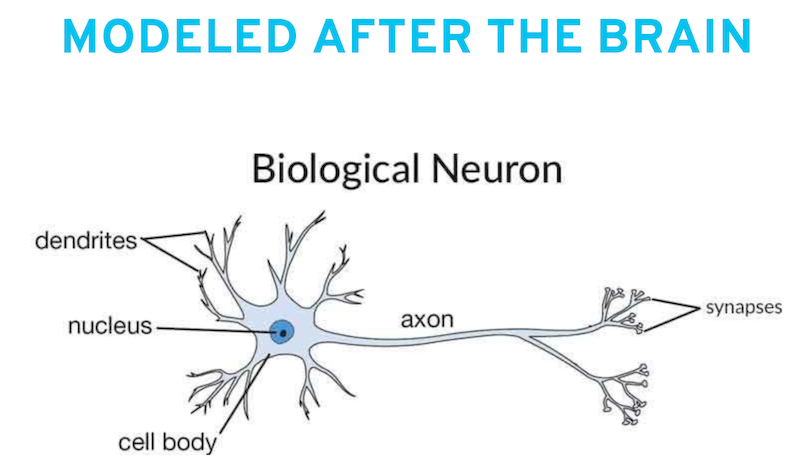
The only thing this image is trying to explain, is that our brain is made up of neurons that:
- take in inputs;
- do some form of processing;
- produce an output.
And is basically the end of the comparison to our human brain.
In practice, and without going into too much detail, this results into a basic building block consisting of two parts:
- a linear part;
- a non-linear part.
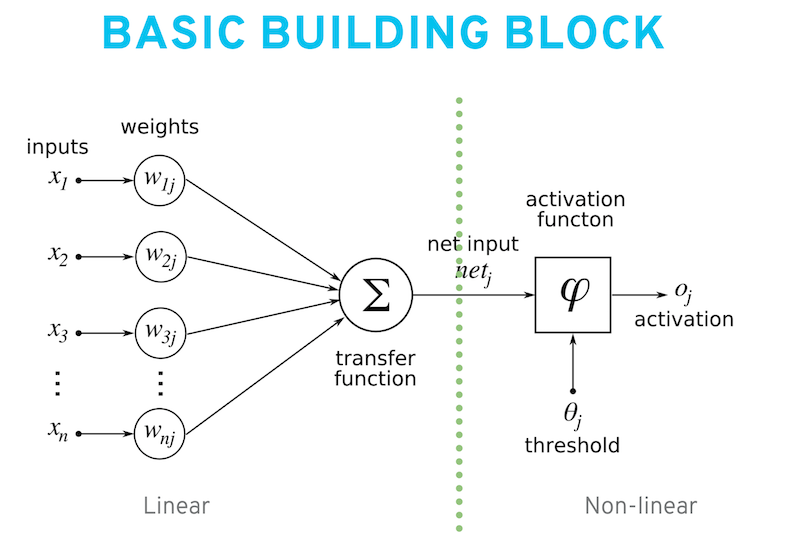
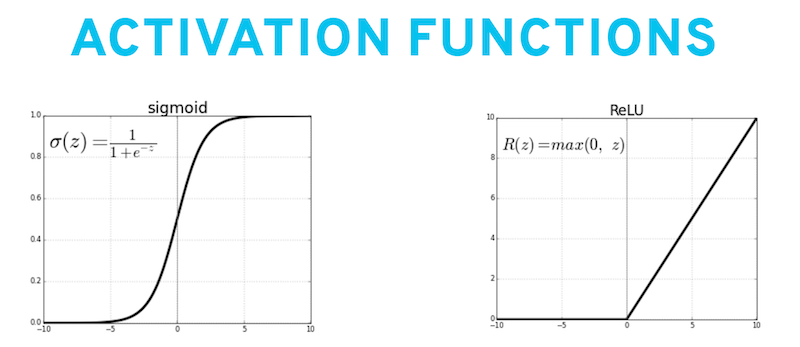
The linear part is multiplication and addition, and the non-linear part makes use of what is called an ‘activation function’, which transforms an input non-linearly. Below are two examples of popular activation functions.
Note: Granted, this is a bit technical, but do not worry, you do not need this kind of specialized knowledge to use the current state of the art. However, it might later help you understand what is really going on, and should show you there is little magic involved.
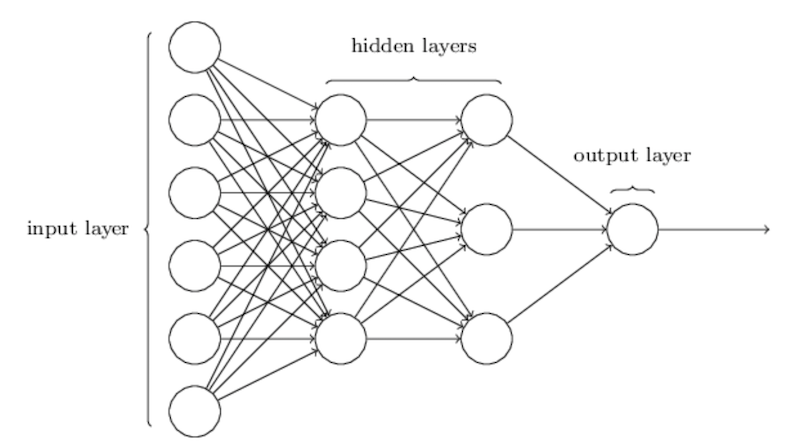
If we stack a lot of these building blocks on top of each other, we get what is called: “a neural network”.
The “input layer” is the inputs we described above (image, text…), the output layer is the prediction the network makes (“spam or not”,…). In between we find the “hidden layers” where (a lot of) computation is going on.
Deep Learning
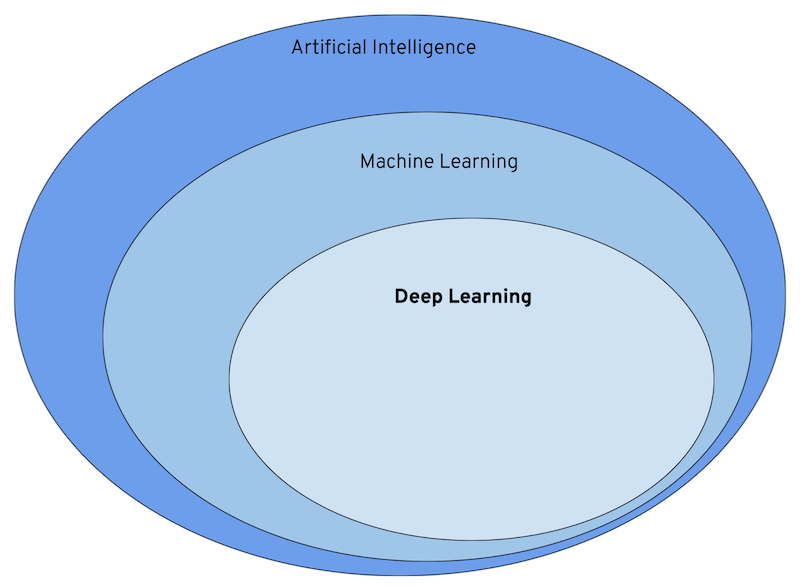
Finally, we get to Deep Learning, which in turn is a subset of machine learning.
Computer Vision
To understand what it is and how it works, we will discuss some examples, starting with computer vision.
We start our journey with ImageNet which is both a dataset as well as a competition (more on that below).
The dataset consists of ~1.1 million labeled images, spread over 1000 different classes (“speedboat”, “ballpoint”, “stove”, “trench coat”, “trombone”…). Click here for a full list of all the classes.

Between 2010 and 2017, there was a yearly competition (ImageNet Large Scale Visual Recognition Challenge - ILSVRC) that brought researchers worldwide together to compete in predicting the class that was depicted in an image.
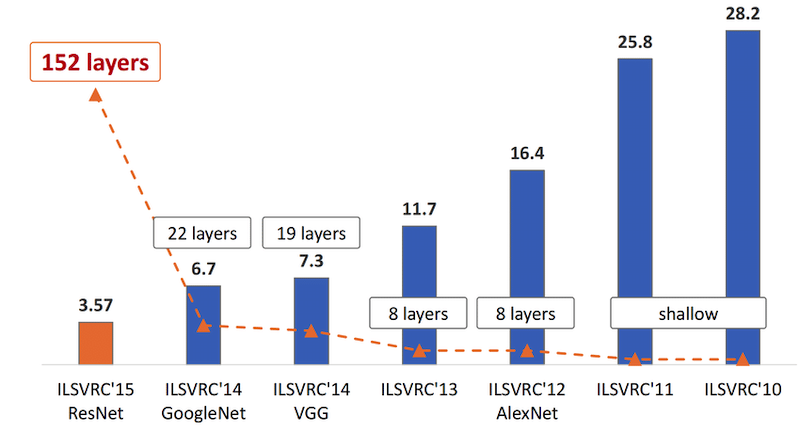
The graph below shows the winner results from 2011 to 2016.
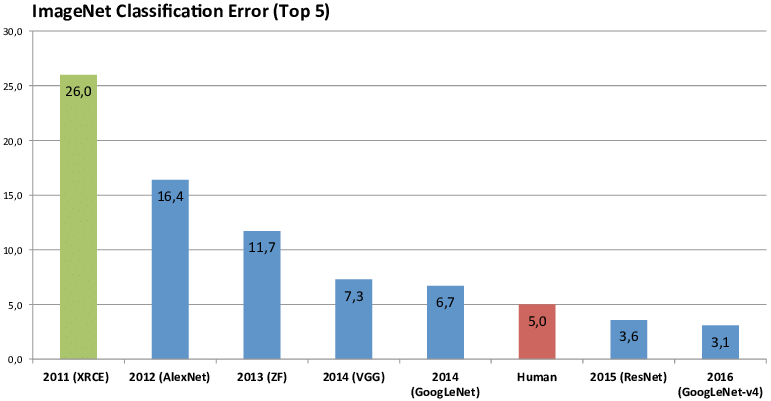
In 2011, the winner was able to predict the correct class for an image in about one in four (~26%). (Top-5 prediction means the correct answers was in the top-5 suggestions from “the algorithm”).
Important here is that this was a ’traditional’ computer vision approach, handcrafting a lot of functionality to detect specific traits (for examples to detect edges).
In the 2012, an entry named “AlexNet” beat the competition hands down, improving accuracy with about 10% over the previous year. What is interesting about this approach is that is does not contain any specific logic related to the classes it was trying to predict. This is the first time deep learning made its way onto the scene.
The years after that, all winners were using deep learning to keep significantly improving the state of the art.
In 2015, it even started beating ‘human level’ performance on ImageNet. The picture below gives you an example of how you can interpret that. Can you easily identify pug vs cupcake?

If we think back to stacking those building blocks, we can see that over the years, there are increasingly more “layers” in those networks, which is where we get the name “deep” learning from. (note the picture below in reverse chronological order)
In traditional machine learning, experts use their knowledge and time to craft a set of features that can be extracted from the input, and can be used to train a classification network to produce an output.
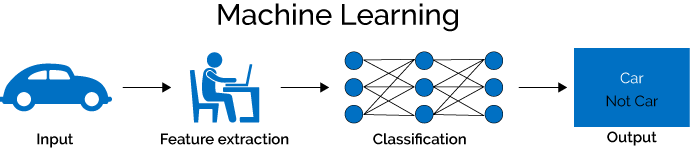
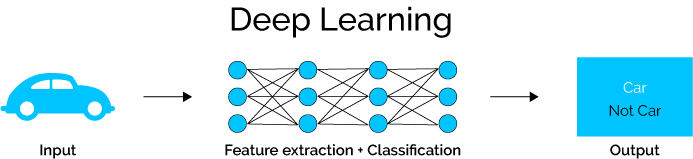
If we compare that to how deep learning works, we see that deep learning takes care of both feature extraction and classification.
In computer vision, we distinguish a set of different applications.
Classification tells you what class is in the images.

Classification and localization tell you which class it is in the image and where that class is by predicting the bounding box.

Object detection makes a prediction for all classes it thinks are in the image, together with their bounding box.

Scene segmentation predicts the classes in the picture as well as the countour of that object. In practice this comes down to predicting a class for every pixel of the image.

Natural Language Processing
A second application we will look at is natural language processing, which as written above, is quite easy for humans but very hard for computers.

A well-known example is spam classification. Given an incoming mail, should this be marked as spam or be allowed to move the user’s inbox?
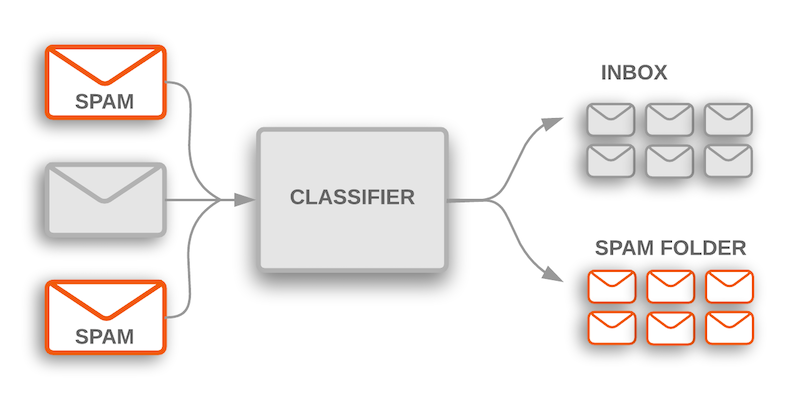
More generally, you can apply text classification to a broad number of topics.

It can also be used to summarize documents…
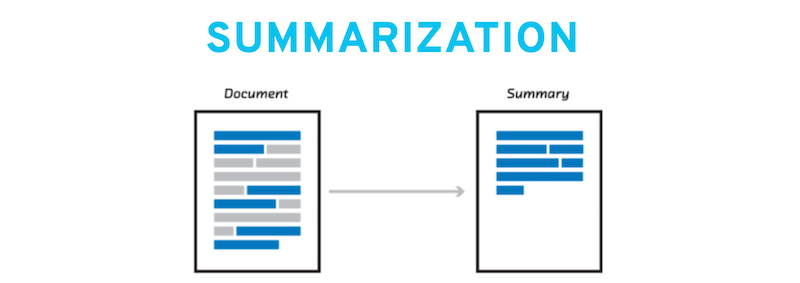
or for automatic translations. When Google started offering these machine translations the results were a bit disappointing, but over time the algorithm improved, a lot - although it is not perfect. :)
![]()
However, over time, more and more questions of true understanding came up. Is the network simply learning all the examples? Does it truly understand the inputs it is being shown?

So researchers continued to push the envelope. Instead of classifying an image, they thaught it to describe the picture. Look at the picture below, where some pictures are described accurately (on the left), while some are captioned with minor error (middle) and some need some additional learning (right).

The next step was to train a network to answer questions related to an image. Below are some examples of good and bad ones. The network is capable of understanding what vegetable is on the plate, as well as detecting the second bus in the background.

When deep learning is discussed, it is often referred to as a “black box”. We do not know what is going on or why it makes a certain decision. In the picture the network visualizes and underlines the ‘classes’ it recognizes.

Without giving a formal definition, we can think of deep learning in the following way:

A few special cases
Below we will discuss some cool things deep learning has made possible. Although they might not seem directly applicable in a business environment, it is important to be aware of current (and future) capabilities to see and understand what the technology is capable of.
Neural Style Transfer
Using what is called Neural Style Transfer, combining the scene from one photo and the graphic style from another, you can create new and creative images.
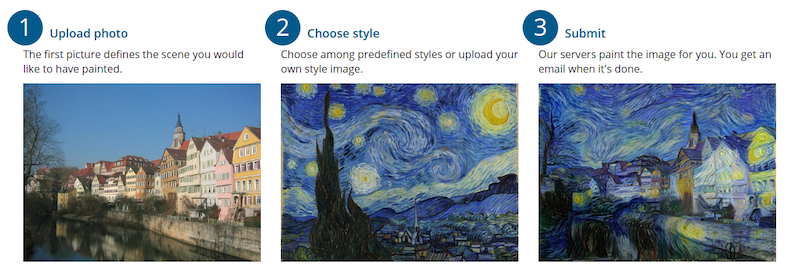
Image2Image
Using Image2Image translation, you can create new images from existing ones, for example changing horses to zebras, or changing the season the picture was taken in. The last example is great for creating synthetic data to train networks, for example, if you are training a self-driving car, you can create “winter photos” without actually have to wait for winter to take them.

This also works for movies, however, the tail of the zebra might need some improvement.

Noise2Noise
NVidia, one of the leading companies in AI hardware, also does some great research. In their recent (Oct 2018) Noise2Noise paper they describe an image restoration process, which leads to some amazing results. The cool thing here is, that they learn without looking at the clean image, so only observing the corrupt data!

Neural Photo Editor
Photoshop is the default image editing software for most professional designers. But would it not be cool if the editor understood what you were trying to do? If you change the color of the hair, it would know where the hair is, and how it gets affected by the light falling on it.

Glow
OpenAI, founded by Elon Musk, Ilya Sutskever and Sam Altman, is on a mission to discover Artificial General Intelligence (AGI) and on their path they come up with cool research such as Glow, which allows you to tweak picture characterics.
By simple dragging the slider, you can tweak the smile, age, …
Try it yourself on the OpenAI website.

AlphaGo - AlphaZero
In 2016, DeepMind - acquired by Google in 2014 - was able to beat the reigning world champion of Go, Lee Sedol, in 4 games to 1.
Up until that point, no one really believed computers would ever be able to beat a human at the game of Go. In the years to come, DeepMind improved its algorithms and the current version “AlphaZero” is currently perceived as the best Go player, and was able to beat AlphaGo 60-40 after only 34 hours of training.
For those interested, the 2016 story is captured nicely in the Netflix documentary “AlphaGo”

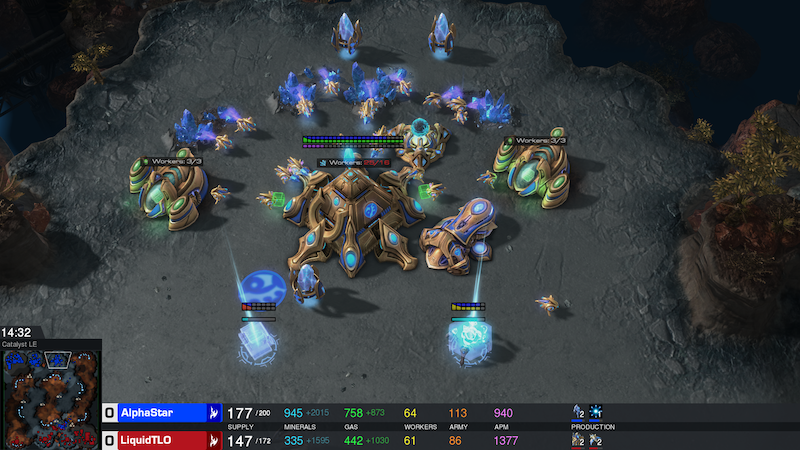
AlphaStar
DeepMind’s AlphaStar was recently able to beat two top players (“TLO” and “MaNa”) in the realtime strategy game of Starcraft II. The game provides significant challenges for an AI system to overcome such as:
- imperfect information: with chess and go - all information is known;
- real-time: players perform actions continuously instead of in alternate turns;
- an insane amount of possible actions to be taken at a given step.
The future
So what does the future hold in store for practical use cases?

Self-driving cars
Self driving cars is one of the most well-known examples, with arguable one the biggest impacts so far… But how cool would it be to be able to sit back, read a book or take a nap, while being driven to basically anywhere.
And while a lot of companies are persuing this future, and some practical trials are active at the moment, no one can predict how soon that future will be mass-adopted (or adoptable).

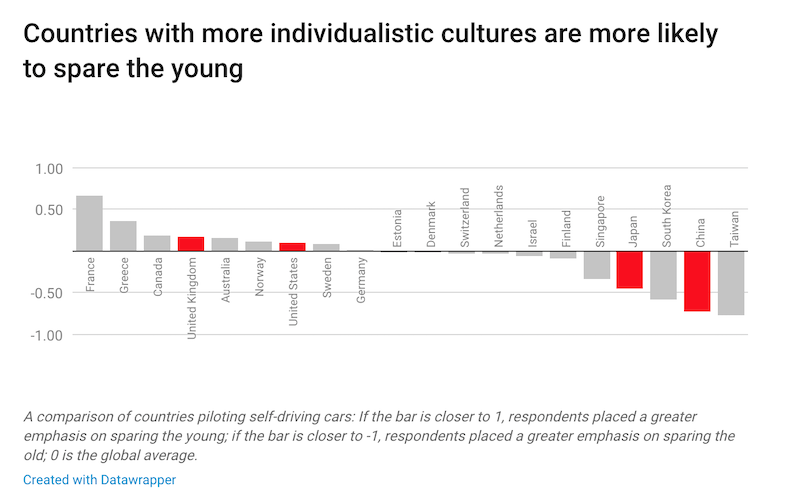
However, apart from technical challenges, this also poses some moral questions. The people at MIT created a small experiment, to “gather the human perspective”. If you click the “start judging” button, you will be able to shed your own light on what the AI should decide in a given situation. Note that the dilemma’s get harder after a few examples…
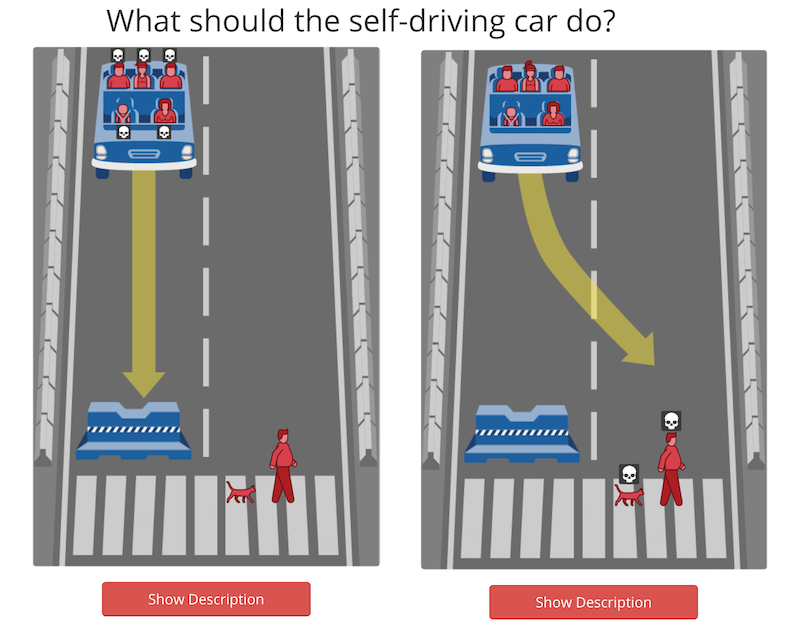
From their results, they found that there is no real one answer to these questions, and depending on the culture, people would either save the youth versus the elderly. What would/did you select?
Voice Assistants
Voice assistants are another category of new solutions that take your input and perform a given task on your behalf. Although are heavily being pushed, their performance tends to vary, but they offer the rise to some cool and new types of applications.

Recommendation Engines
One popular application of deep learning that we have not discussed so far is recommendation engines. One obvious example is Netflix, that holds so much content that is extremely hard for users to browse and find (new) shows they would like. Instead, Netflix tries to recommend series that they think would interest you, based on your preferences and what others like you have enjoyed, and suggest why they think you would like it
But Netflix takes it a step further, they have started generating visual content based on what they think will interest you most.
It is easy to see that the same reasoning applies to Spotify.
Text Prediction - Speech
Google’s Gmail has started making predictions as to what you could be typing. They started with adding name suggestions, but you might think that was to make users comfortable with the suggestions, and then moved on to suggesting more context-related endings…
Duplex, another example from Google, was demoed in May 2018, was able to have an algorithm make a call to book a hair appointment and restaurant reservation on its own. You can find the examples on Google’s blog, listen carefully to the recordings, as the AI had to overcome:
- poor English;
- interruption;
- implicit statements.

Content Creation
This one might seem less “business”-related, but the generated painting below, the “Portrait of Edmond Bellami”, was generated by what a Generative Adverserial Network (GAN), and was sold for $432,500 at Christie’s, so there might be a place for “AI art”…

Industry
In retail or industry in general, you could scan packages to see what ingredients are included…

… or whether you have defects in your pruduction output.

Structured data
Rossman is Germany’s second-largest drug store chain, and they are known for the Rossman Challange, asking people to predict the sales at their store at a given day, given weather, holiday, weekday… It is one of the pinnacle examples of structured data in artificial intelligence, a field that holds great potential, but is oftern overlooked by researchers.
You can think of structured data as data in databases or excel sheets, which is contrary to unstructured data such as images or text.

Why now?
So why is this working now?

Data, data, data
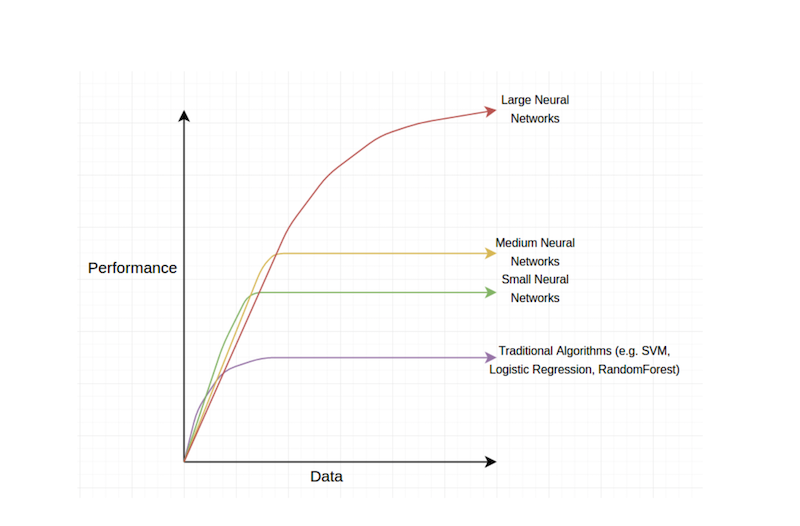
First of all, the amount of data we have at our disposal. In contrast to humans, computers need to look at a lot of examples (we will nuance this below) to learn concepts. That data was not around in the beginning of the 2000’s but now it is…

The reason why data is so important, is that deep learning algorithms get more data hungry, the larger/deeper they get, and we have seen that deeper networks tend to perform better.
GPU hardware
Secondly, the availability of hardware. Deep neural networks, in essence, consist of a lot of multiplications and non-linearities, and at training time they will look at a lot of data, which requires powerfull computers, more specifically graphical cards, as they tend to offer the best results. Note that some companies are also creating AI-specific hardware to increase performance even further.
In the picture below, we specifically depict an NVidia GPU, as they are, at the moment of writing, the only GPU brand that is supported by the major AI frameworks.

Algorithms
Although the ideas existed in the 1950’s and most of the core algorithms stem from the 1980’s, some recent breakthroughs in supporting networks getting deeper have contributed to deep learning becoming the workhorse of AI.
The details of these algorithms are far beyond the scope of this text.

AI Software Frameworks
Fourth and final factor contributing to the current success of AI, and often overlooked, are the frameworks to implement it, allowing developers to implement algorithms without having to write everything from scratch, or even know all the details. The frameworks offer a valuable layer of productivity abstraction.

Some hardcore myths
Last but not least, we discuss some AI myths.

PhD requirement
Contrary to popular belief, you do not need a PhD to apply AI and deep learning today. There are a lot of resources, frameworks and even pretrained models out there to get you going. If, however, you want to get into reseach, muchlike in any field, a PhD might be a good idea.
Replaces domain experts
From experience it is usually the opposite. Deep learning is really goed in learning to map inputs to outputs but we still need people who understand the domain very well, to get the correct data to learn from and to see if the results being produced are actually any good.
Big data
Above we mentioned that deep learning models are data hungry, and the more data they see, the better they get. Luckily, there are ways to reuse a lot of knowledge and tweak it to our benefit, giving us excellent results without needing 1000’s of images.
GPU galore
GPUs are used to train your network but unless you are into researching the latest and greatest, you can easily get started with two or even one… As someone once said, “if you have been collecting and cleaning your data for a couple of weeks, who cares if your algorithm takes 20 minutes longer to train”.
Limited problem scope
Deep Learning is a general approach to mapping inputs to outputs without being explicitely programmed, by looking at a lot of examples. Therefore, the technique can be applied in almost any area…
Experts are hard to find
Without being overly optimistic, getting started with AI is not rocket science nor is the technology magic in itself. Over time, the barriere to entry will go down further and further, as more abstraction layers are being made available.
For example, all the cloud vendors are offering AI-as-a-service so people can make use of the technology without knowing most of the details. A lot will depend on your use case, and will reflect a typicsl build-vs-buy decision just like in any project.
The end
We hope this post gives you a good overview of:
- what AI, ML and deep learning are;
- a little bit of how they work;
- examples of what they can do for you;
- why they work now.